
We introduce 3D Gaussian blendshapes for modeling photorealistic head avatars. Taking a monocular video as input, we learn a base head model of neutral expression, along with a group of expression blendshapes, each of which corresponds to a basis expression in classical parametric face models. Both the neutral model and expression blendshapes are represented as 3D Gaussians, which contain a few properties to depict the avatar appearance. The avatar model of an arbitrary expression can be effectively generated by combining the neutral model and expression blendshapes through linear blending of Gaussians with the expression coefficients. High-fidelity head avatar animations can be synthesized in real time using Gaussian splatting. Compared to state-of-the-art methods, our Gaussian blendshape representation better captures high-frequency details exhibited in input video, and achieves superior rendering performance.
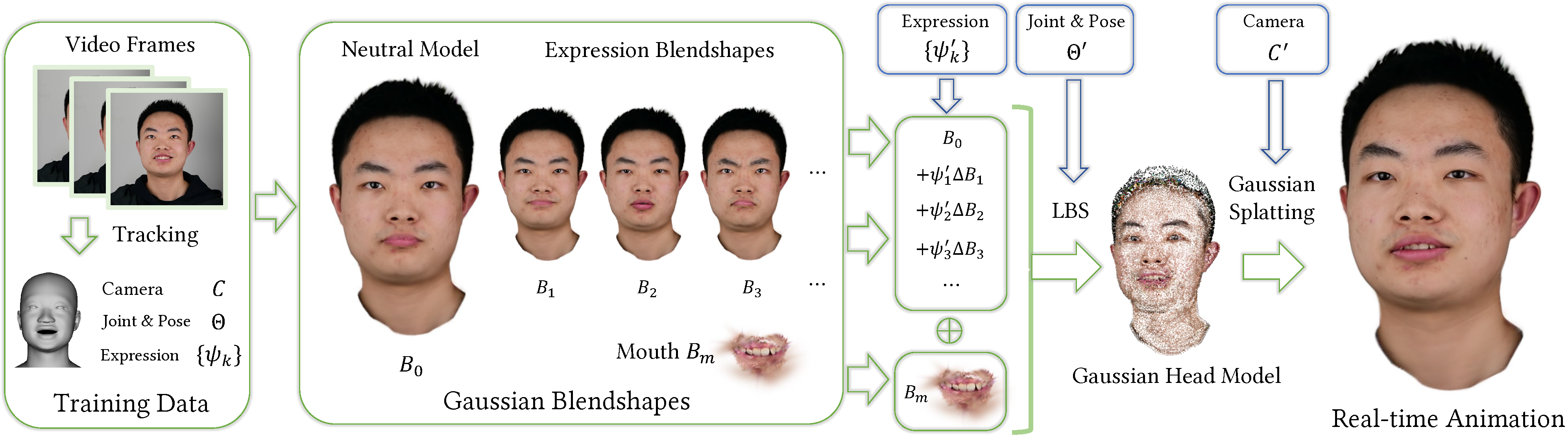
Taking a monocular video as input, our method learns a Gaussian blendshape representation of a head avatar, which consists of a neutral model \( B_0 \), a group of expression blendshapes \( B_1,B_2,...,B_K \), and the mouth interior model \( B_m \), all represented as 3D Gaussians. Avatar models of arbitrary expressions and poses can be generated by linear blending with expression coefficients \( \psi'_k \) and linear blend skinning with joint and pose parameters \( \Theta' \), from which we render high-fidelity images in real time using Gaussian splatting.
We compare our method with three state-of-the-art methods. Our method is better at capturing high-frequency details observed in the training video, such as wrinkles, teeth, and specular highlights of glasses and noses. A unique advantage of our method is that it only requires linear blending of Gaussian blnedshapes to construct a head avatar of arbitrary expressions, which brings significant benefits in both training and runtime performance. Our method is able to synthesize facial animations at 370fps, over 5x faster than INSTA and about 14x faster than NeRFBlendshape.
We present a novel 3D Gaussian blendshape representation for animating photorealistic head avatars. We also introduce an optimization process to learn the Gaussian blendshapes from a monocular video, which are semantically consistent with their corresponding mesh blendshapes. Our method outperforms state-of-the-art NeRF and point based methods in producing avatar animations of superiorquality at significantly faster speeds, while the training and memory cost is moderate.
@inproceedings{ma2024gaussianblendshapes,
author = {Shengjie Ma and Yanlin Weng and Tianjia Shao and Kun Zhou},
title = {3D Gaussian Blendshapes for Head Avatar Animation},
booktitle = {ACM SIGGRAPH Conference Proceedings, Denver, CO, United States, July 28 - August 1, 2024},
year = {2024},
}